

Big Data's Next Evolution: Relevancy – Gravity
// 1.23.14
Big Data’s Next Evolution: Relevancy
Everyone is always asking me how big our ontology is. How many nodes are in your ontology? How many edges do you have? Or the most common – how many terabytes of data do you have in your ontology? We live in a world where over a decade of attempted human curation of a semantic web has bared very little fruit; it is quite clear to everyone at this point that this is a job only machines can handle. But yet we are still asking the wrong questions and building the wrong datasets.
Natural Language Processing
The exponential growth of data being created on the web has naturally led to a want to categorize that data. Facts, relationships, entities – that is how those of us who work in the semantic world refer to structuring of data. It’s pretty simple actually. It happens so quickly in our subconscious minds as humans that it’s incredibly easy for those who don’t work on teaching machines to do it to take it for granted. It’s also not a new field; deconstructing human language into structured data (Natural Language Processing) has been around for almost 40 years. NLP can take the sentence “Jim is writing an article about why people ask the wrong questions about ontologies” and structure it into –
NNP = Proper Singular Noun
VBZ = Verb, 3rd Person Singular Present
VBG = Verb/Present Participle
DT = Determiner
NN = Singular Noun
IN = Preposition
WRB = Adverb
NNS = Plural Noun
VBP = Verb, Non 3rd Present Singular Person
DT = Determiner
JJ – Adjective
That’s pretty impressive – a machine just did that. I bet you couldn’t label all of those – maybe your high school English teacher could. But you can understand what the sentence means in less than a hundred milliseconds after reading it, and that’s what really matters. The machine that did the above has no understanding of the information the sentence conveys. Its job is to decompose unstructured language into structured data that another system might be able to understand.
That’s where semantics come in. Semantics try to understand the relationships between things (we call them entities, or nodes if you really want to go down the rabbit hole).
Jim [PERSON] -> writes [ACTION] -> sentence [THING]. Seems like a something a child could do right? The human brain is amazing.
Semantics
Try this one:
“I paddled out today, and dude, I look like a lobster.”
What does that mean? We know someone is talking about themself because of the leading personal pronoun, NLP won’t help us with the rest but with “today” most good entity extraction engines can tell us we’ve got a time period (maybe even future intent – exciting!). We can use publicly available ontology data from Freebase/Wikipedia/DBpedia (or many others) to decide paddle [disambiguate to CANOEING], dude [ PERSON – TYPE OF GENDER] and lobster [COMMERCIAL CRUSTACEANS].
So we’ve got
[PERSONAL REFERENCING]
[CURRENT TIME PERIOD]
[CANOEING]
[GENDER MALE]
[COMMERCIAL CRUSTACEAN]
This is like an ad server’s dream! Whoever tweeted this needs to be shown Lobster ads for months. I actually have set up sites with this sentence and tasked many other IAB focused ad systems to recognize it and it’s all Red Lobster all the time. I’ve enjoyed many half-off cheese biscuits in the last 12 months. R&D sometimes bears not only fruit but also cheesy biscuits.
But I wasn’t talking about canoeing or lobsters. When I’m not building things here at Gravity I surf, and unfortunately occasionally I do get sunburned – sometimes to the point of being told I look like a lobster. That’s what I was conveying in my < 140 character tweet – why is it so easy for us to understand but so hard for a machine to understand? But maybe this is just a funny edge case. You can confuse any computer system if you try hard enough right?
Unfortunately this isn’t an edge case. Different lexicons were different languages or different colloquial terms specific to particular industries before Twitter. This is no longer true. 140 characters has not just changed people’s tweets it has changed how people talk on the web. More and more information gets communicated in smaller and smaller amounts of language, and this trend is only going to continue.
So why is there not a semantic web? Why can’t we solve this yet? Why can’t we understand that “I’m a lobster” means you are sunburned and not that you want cheesy bread? (ok – I agree this isn’t the greatest example because who doesn’t want cheesy bread).
What Does it Mean?
I believe the reason that there are not hundreds of companies exploiting machine learning techniques to generate a truly semantic web is the lack of weighted edges in publicly available ontologies. Lobster and Sunscreen are 7 hops away from each other in dbPedia – way too many to draw any correlation between the two (any article in Wikipedia is connected to any other article within about 14 hops, and that’s the extreme. Completed unrelated concepts are often just a few hops from each other).
But by analyzing massive amounts of both written and spoken English text from articles, books, twitter, and television it is possible for a machine to automatically draw a correlation and create a weighted edge between the Lobsters and Sunscreen that effectively short circuits the 7 hops necessary. Many organizations are dumping massive amounts of facts without weights into our repositories of total human knowledge because they are naïvely attempting to categorize everything without realizing that the repositories of human knowledge need to mimic how humans use knowledge.
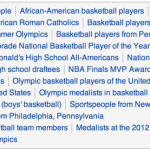
For example – as of today Kobe Bryant is categorized under 28 categories in Wikipedia, each of them with the same level of attachment (1 hop in a breadth or depth first traversal).
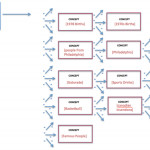
But when you are at a coffee shop and overhear the person next to you mention Kobe Bryant, what are you able to infer they are talking about? “Basketball” or “American Roman Catholics”. How is the human brain able to do that so quickly yet machines can get so confused? It is not due to lack of technical processing power, Moore’s law slowing down, or the thickness of our silicon wafers – it’s because of the data. For those of you who work in the world of graph theory – run a standard few hop depth first traversal from Kobe Bryant on Wikipedia and attempt to coalesce around a common category.
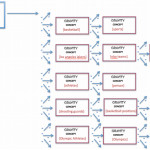
This is a small example of what you’ll end up with – So when someone tweets about Kobe Bryant are they talking about people born in 1970, Pennsylvania, Food and Drink, or Canadian inventions? This is a common example of how confused a machine can become when the distance of unweighted edges between nodes is used as a scoring mechanism for relevancy. But what happens if we weight our edges. The same Wikipedia nodes with path costs can be run through a traversal algorithm that calculates those costs and we get the following:
Our machine is starting to think like a human.
Algorithms and Processors Aren’t Enough
Weighted path traversal is not new. Dijkstra invented his algorithm in 1956 so the answer has been around for a long time. Granted, the processing power and memory necessary to leverage a traversal algorithm like Dijkstra’s, and score path costs and not just distance between nodes across massive data sets has only recently become available to the average startup in just the last few years. That’s a huge win for all of us, but the data and ontologies to actually do it are still not publicly available.
The above example forces us to ask, “how important is it that Kobe Bryant was born in 1979 or that basketball was actually invented in Canada?” If you are part of the 99.9% of the world that is not curating an ontology the answer is probably “not important at all.” But if you are working on either an open source or proprietary ontology attaching Kobe Bryant to 1979 not only makes you feel like you just categorized another small piece of the world’s knowledge you also just grew the size of your ontology. You are part of the “ontology size matter’s club”.
I propose as an industry we begin to focus more on relevancy and less on factual accuracy. The above flawed traversal is actually 100% factually accurate. Kobe Bryant was born in 1979, he is (or was) sponsored by Gatorade, Gatorade is a Drink, and Basketball was invented in Canada. But even now that you know all those facts when you hear someone talk about Kobe Bryant tomorrow you will still know they are talking about Basketball. The human mind is an amazing thing. We subconsciously weight (and re-weight) all edges in our brain in real-time to focus on relevancy. We need our centralized repositories of human knowledge to do the same.
What’s Next
The only way we will actually get to a truly semantic web is when machines are able to think (or more accurately – perform) like we do. The processing power, technology and algorithms to do that exist today. Unfortunately, the datasets to unleash that upon are inherently flawed and that is why we still see Red Lobster ads on Sunscreen pages.
We need to become much less focused on adding facts to Freebase, dbPedia, and the other publicly available ontologies and much more focused on weighting the edges between the facts that we are adding. This is how we create a truly semantic web.
The answer lies in the data. (When does it not?) But not in the data available on a web page or in a set of thousands of web pages recommended by a particular algorithm. LSI, PLSI, LDA, and much less complex “keyword bag” algorithms are only aware of the context of the information in the datasets fed to them. These base algorithms (LDA especially) are incredibly useful but without the context of a global human knowledge base you cannot build an interest graph, and you cannot build a semantic web. Ontologies become necessary as we attempt to solve this problem.
If you feed any of the above algorithms 10 articles a person read about snowboarding they will successfully recommend other snowboarding articles, but are unaware that snowboarding and surfing are two sports that go hand in hand, people who enjoy one usually enjoy the other. An ontology with weighted edges is necessary to make that relevant yet tangential connection, and avoid the dreaded “filter bubble”.
So to all of my semantic colleagues out there, maybe we should shift our thinking and begin to use a different yardstick to measure the quality of our knowledge repositories. For 99% of all use cases we have enough nodes – we have successfully deposited the majority of places, events, people, thoughts, and most other tangible and intangible things in the world into our data stores – and a good part of the population has access to all of it from the smart phone in their pocket. That is an incredible feat. But it’s only half of the equation.
We still have yet to map the data into a format that mimics how the human mind thinks. The way to do this is to begin weighting the edges that interconnect the nodes and facts that we are adding every day. This requires us to raise the bar from factually accurate to actually relevant. Kobe Bryant -> Philadelphia is factually accurate, but Kobe Bryant -> Basketball is actually relevant. Today’s ontologies make no distinction between those two facts, and without that distinction a machine will never be able to create the semantic web we have worked towards for almost a decade. Every fact in Wikipedia is added by a human. Weighting edges between those facts sounds like a monumental task. But crowdsourcing the creation of a central repository of all human knowledge sounded impossible a little over a decade ago, and we’ve done a very good job of that.
It wasn’t too long ago that running an elastic cloud infrastructure was something that was available to only the largest internet companies in the world. Amazon changed that. Now one smart engineer can turn an idea into a company for $50 a month. But there is still a large divide between companies that can use machines to do web scale semantic analysis of content and the one smart engineer. The relevancy defining edge weighting algorithms of Google’s Knowledge Graph, Facebook’s Open Graph, and Gravity’s Interest Ontology are closely guarded company secrets. Imagine if that data was available to everyone – it would be as disruptive as AWS. The Internet would be a better place.
Gravity Approach
At Gravity we have joined many publicly available and our own internally generated ontologies to create a large interest based undirected graph that leverages many forms of edge weighting to solve the above problem. We built and protected this as a company secret for many years. In the last year we have realized that our mission – building a web scale personalization platform – takes a lot more than an ontology with weighted edges. It’s an iceberg problem that looks simple when you are designing collaborative filtering for an app or yield optimizing by user demo for your site, but our mission is a platform for the entire web. A relevancy based ontology with weighted edges is necessary, but it is just the beginning.
Internally we are formalizing a plan to develop an open, centralized place to allow human and machine curation of ontology edge weights for the community. We plan on contributing a significant amount of our data to get the project started. More on that to come. Until then, as a community I believe we should begin to focus more on relevancy and relationships, and less on the continued addition of facts to our publicly available semantic resources.
Read this article:
Big Data's Next Evolution: Relevancy – Gravity

