
Google Cloud Platform Blog: Easier, faster and lower cost Big Data …
Google Compute Engine VMs provide a
and reliable way to run
. Today, we’re making it easier to run
Hadoop on Google Cloud Platform
with the Preview release of the
Google Cloud Storage connector for Hadoop
that lets you focus on your data processing logic instead of on managing a cluster and file system.
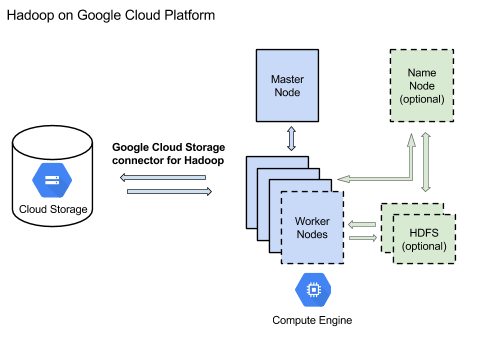
Diagram of Hadoop on Google Cloud Platform. HDFS and the NameNode are optional when storing data in Google Cloud Storage
In the 10 years since we first introduced
— the basis for Hadoop Distributed File System (HDFS) — Google has continued to improve our storage system for large data processing. The latest iteration is
.
Today’s launch delivers exactly that. Using a simple connector library, Hadoop can now run directly against Google Cloud Storage — an object store built on Colossus. That means you benefit from Google’s expertise in large data processing.
Here are a few other benefits of running Hadoop with Google Cloud Storage:
Compatibility: The Google Cloud Storage connector for Hadoop code-compatible with Hadoop. Just change the URL to point to your data.
Quick startup: Your data is ready to process. You don’t have to wait for extra minutes or more while your data is copied over to HDFS and the NameNode comes out of safe mode, and you don’t have to pay for the VM time for data copying either.
Greater availability and scalability: Google Cloud Storage is globally replicated and has higher availability than HDFS because it’s independent of the compute nodes and the NameNode. If the VMs are turned down (or, cloud forbid, crash) your data lives on.
Lower costs: Save on storage and compute: storage, because there’s no need to maintain two copies of your data, one for backups and one for running Hadoop; compute, because you don’t need to keep VMs going just to serve data. And with per-minute billing, you can run Hadoop jobs faster on more cores and know your costs aren’t getting rounded up to a whole hour.
No storage management overhead: Whereas HDFS requires routine maintenance — like file system checks, rebalancing, upgrades, rollbacks and NameNode restarts — Google Cloud Storage just works. Your data is safe and consistent with no extra effort.
Interoperability: By keeping your data in Google Cloud Storage, you can benefit from all of the other Google services that already play nicely together.
Performance: Google’s infrastructure delivers high performance from Google Cloud Storage that’s comparable to HDFS — without the overhead and maintenance.
To see the benefits for yourself, give Hadoop on Google Cloud Platform a try by following the
.
We would love to hear your feedback and ideas on how to make Hadoop and MapReduce run even better on Google Cloud Platform.
-Posted by Jonathan Bingham, Product Manager
Link to article:
Google Cloud Platform Blog: Easier, faster and lower cost Big Data …


{kind=link}