
Office of the CTO | Storage and Big Data in 2014

Last year, I made several predictions about storage and big data – including one about the mad dash for software-defined storage (SDS). Well that’s certainly turned out to be true, with literally dozens of new products hitting the market this year with various attributes of software-defined storage! VMware also made some big news in this space with the launch of VSAN Beta at VMworld.
The tricky part is identifying what qualifies for legitimate software-defined storage. We’re seeing both hardware and software-only products being positioned as software-defined. The best way to think about this space is that hardware-based storage can be software-defined if it has a fully software-controllable API that allows simplification of provisioning and management. The other, arguably more important part of software-defined storage is emerging as we speak – storage implemented as scale-out software on servers.
Exciting times in the storage market, and I’d like to share my predictions around what we should expect to see in this space next year:
Prediction #1 – Increase in Cloud Storage as a tier of the enterprise
Increasingly, we’ll see cloud-connected object storage as a useful tier of storage for core enterprise. The most likely use case is as a replacement for cold data tiers, tape and as a conduit for archive data. Many technologies are already being adapted to transparently archive to the cloud. As a result, some traditional storage is being replaced by these cloud services.
Prediction #2 – Wide Scale Return of Server Storage
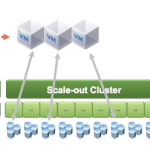
Today, server deployments use external storage in the majority of deployments — be it a SAN or NAS device. It’s a custom hardware storage device, exporting storage using various standard protocols over a network to the server. There are some exceptions — at the low end, some servers have local disks to provide low cost built in storage, and at the high end big data clusters using Hadoop are using local disks in servers to provide a solution for peta-byte scale file storage.
This year, I expect to see a substantial growth in the use of server storage. I’ve heard arguments made that practically all storage is constructed from comodity severs plus software, but here I’m being much more specific and ruling out large, vertically scaled SAN/NAS storage solutions. Increasily, we’ll see an emerging pattern of scale-out storage solutions, using bricks of smaller quantities of disks, co-located with CPU and memory, which are interconnected on a fast network. These servers are running pure software – no special hardware or network is required implement storage services.
Lets look at what’s enabling this. There are several trends occurring concurrently that have made it possible to provide high performance, high scale, reliable storage on commodity servers:
New distributed system software: we’re now seeing several new approaches of providing reliable persistence across distributed clusters of servers. This requires significantly complex software, especially when you need to guarantee consistency of writes to the application — since the local disks in the servers are unreliable. And this also means when a host fails there needs to be other copies of the data stored on other hosts. To meet the consistency requirements this requires writes being synchronously replicated to other hosts using distributed transactions across the network. Several new distributed file systems (e.g OneFS) and block stores (ScaleIO, VSAN, Nutanix) are using these techniques, forming the base for a new class of storage using servers.
Fast networks: attaining good performance in a distributed storage system requires fast access to data on remote servers, and the ability to commit writes between hosts rapidly. With the onset of 10 gigabit, inter-host transactions in under 50us are possible, making it feasible to commit to remote persistence with little contributing latency affect. With VSAN virtual, we are seeing I/O latencies lower than a traditional SAN using this approach. The OneFS team is seeing meta-data intensive file system operations with high throughput and client latencies less than 150us – both which the fast network plays a heavy role.
Solid State Disks: the ability to commit to low latency stable storage is fundamental to allowing these fast-distributed transactions. In addition, the throughput of SSDs for random I/O enable a significant amount of throughput, especially when multiple SSDs across hosts are clustered together as a pool.
The primary motivating factors are ease of administration, cost and performance. Christos Karamanolis does a great job in his predictions describing the coming change in storage management in in his 2014 prediction blog. On the cost front, typical storage servers provide capacity for around $.20/Gigabyte, although I’ve seen customers configuring super-dense server storage as low as $.10/Gigabyte. With scale-out software storage, big changes come through extensive use of SSDs, and performance scales up as servers are added.
This year, I expect we’ll continue to see a strong emergence of disruptive scale-out software storage solutions running on server storage.
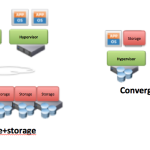
Prediction #3 – A big shift toward Storage and Compute running on the same servers
There are two ways of connecting scale-out software storage to applications — either by connecting a scale-out storage tier via a network to applications, or by converging the storage services onto the same servers as the compute.
The arguments for separated compute and storage are about allowing more optimization for dense compute and dense storage, with full connectivity between all apps in the compute layer and all of the storage. Most of storage as we know it today is network connected – typically LUNs via Fibre Channel networks, or NFS via Ethernet.
Two important trends however argue that a converged model will become more frequently used in the future:
CPU trends towards free: If we assume that we are purchasing servers for storage capacity, the roadmaps show that there is an increasing number of cores per socket over time — for example, this year we can have 12 cores per socket, and in the future we’ll see Intel Broadwell pushing 18 cores per socket, making it economical to have a 36 core, 2 socket storage server. This leaves substantial compute capacity on the converged storage cluster.
Performance: with the availability of a growing amount of flash in each server, applications can optimize around local use of flash to yield low latency, high throughput from the resources in the local cluster.
Simplicity: with a converged compute and storage, we eliminate an entire tier of infrastructure. Anytime complexity is reduced, we optimize cost as well.
In many cases, storage services are provided as a set of virtual machines running along side the compute. This is the model optionally use by software storage solutions such as Nutanix, ScaleIO and Simplivity. Our own VSAN solution is similar, and implements the storage engine inside the hypervisor kernel, to optimize performance of the I/O stack.
The most common model for converged storage will be block storage for virtual machines. Conveniently, the Hypervisor provides a great mechanism for allowing co-residency of storage and compute on the same servers. With local disks providing persistence for virtual machine disks, the converged model provides an optimal model for co-locating the application and its storage. Because there is typically a 1:1 relationship between the application VM and its storage, the hypervisor can use automatic placement and load balancing to move the compute and storage around between servers to attain the best performance.
Converged storage solutions are also the easiest to scale-out. Rather than all storage residing in one large shared storage-cluster, with converged storage a large data center can simply be comprised of many moderate sized clusters. VMs can be placed across a federation of converged clusters, resulting in a larger aggregate cluster size. Automation and balancing is maintained within the clusters. VMs can be moved between clusters if inter-cluster rebalancing is needed.
Prediction #4 – Server Storage as a platform
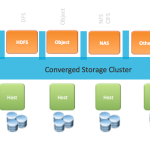
For shared-storage services, this model is best served with a network connected storage service. We can easily assume that shared storage, like NFS, CIFS or Object services would need to reside on a set of storage servers external to the compute layer.
I predict however, that the converged block storage for VMs will increasingly be looked to as a new platform for deploying shared storage services. In this model, the converged storage instructure provides full virtualized management of the local disks, exposing persistence upon which shared storage services can be built. This will bring all the properties of virtualization to local server storage – including ease of provisioning, complete abstraction from the hardware, and a pooled resource management approach to consuming large numbers of devices across the cluster. We can easily provision storage appliances in virtual machines on the converged infrastructure.
These shared storage appliances can use network protocols to export data services to the apps, running in the same tiers of converged storage and compute. NAS is a great example. Lets say we want to provide a service of NAS shares for many applications running in the infrastructure – it’s all of a sudden very straight forward to run a NAS service as a VM on the converged storage infrastructure, exporting NFS and CIFS over the virtual network. In this model, the NAS VM can be deployed with little or no knowledge of the underlying hardware – it simply consumes storage from a resource pool assigned to it. For big data, I do expect the same pattern to have substantial value – by allowing Hadoop’s file system to be implemented on fully virtualized storage pools, we can mix Hadoop with other workloads on the same platform, and bring a new level of multi-tenancy to Hadoop storage.
I’m certainly looking forward to 2014 – and the vibrant ecosystem of distributed storage technologies we will be discussing, architecting, and implementing. What storage trends do you expect to see in 2014?
Read the article:
Office of the CTO | Storage and Big Data in 2014


{kind=link}
{kind=link}
{kind=link}
{kind=link}