

Open Big Data Computing with Julia | Intel Science & Technology …
By Jiahao Chen, MIT and the larger Julia community
Whilst the abstract question occupies your intellect, nature brings it in the concrete to be solved by your hands. — Ralph Waldo Emerson, Prospects, in Nature; Addresses and Lectures
When I first learned about the Julia programming language at the beginning of 2012, I was skeptical about its ability to succeed. Writing a new programming language seemed like an exercise in hubris: Why did the world need yet another one, anyway? Yet after trying Julia, I quickly learned to embrace it.
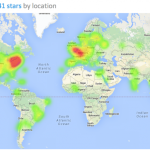
Many others have joined me in becoming Julia users and developers. The Julia homepage now receives over 150,000 visits per month, and there are also now seven Julia user groups in the United States and worldwide, including the local Cambridge Area Julia Users Network. The Julia repository on Github currently has 2,741 stars. As of the v0.2 point release of November 17, 2013, the Julia repository has logged 15,285 commits by 142 developers, who together have written 204,408 lines of code. Additionally, there are 224 officially registered packages representing another 294,655 lines of Julia code.
Global Adoption of the Julia Programming Language, as of November 2013. (Source: Red Dwarf)
Courses using the Julia language are now being taught at MIT (Spring 2013: 18.330; Fall 2013: 18.06, 18.303, 6.337J/18.335J, 6.338/18.337) and elsewhere (Western University Canada, Fall 2013: CS 2101A). Julia is also gaining traction outside academia: Mosek, an optimization vendor, now provides Julia interfaces to their products; quantitative finance users are adopting JuliaQuant for algorithmic trading; and startups like Forio use Julia to create analytics and educational apps for mobile devices and on the web. Posts about Julia make headlines on Hacker News and other high-traffic news sites. Indeed, Julia is poised to become what some have termed “tomorrow’s technology today.”
Julia’s combination of elegance, power and a thriving community is precisely why it is a serious platform for big data applications.
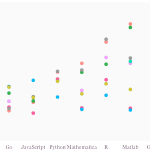
So why Julia? First off, Julia is fast and expressive. Its rich and theoretically elegant type system, combined with runtime inference, allows its just-in-time compiler to produce high performance machine code that takes full advantage of native CPU instructions while avoiding the tedium of explicitly declaring the types of every variable. Julia also wraps best-of-breed C and Fortran libraries and can call them efficiently with minimal overhead. These features, which make Julia excel at numerical computations, also translate into performance for general computing: benchmarks show that Julia code performs within a factor of two of hand-coded C and Fortran routines, while being orders of magnitude faster than comparable high-level languages. Thus Julia sidesteps the usual dichotomy of languages into those suitable for rapid prototyping, such as Python, R and Matlab, and those required for high performance, such as Fortran or C. Julia programmers avoid the complexities that arise from prototyping in one language and deploying in another.
Julia Speed Comparison. Time on Log Scale: Less is Better (Source: The Julia Community)
Equally important to Julia’s growth is a new paradigm for translational R&D that makes collaboration among academia, industry and individuals easier than ever. From the initial nucleus that included MIT professor Alan Edelman, graduate student Jeff Bezanson, Stefan Karpinski and Viral Shah, Julia’s open source MIT license, open-door policy and inclusive ethos have since attracted the best minds to participate, including MIT professor Steven Johnson, a primary developer of the award-winning FFTW library for fast Fourier transforms. The Julia codebase is hosted on Github, where developers constantly discuss how to implement the right language features the right way. Improvements to Julia happen rapidly and frequently, hindered by neither the academic penchant to embargo results until publication, nor the commercial interests to protect intellectual property in ways that hinder verification, reuse, and innovation.
Since Julia’s base code is mostly written in Julia itself, the ease of writing expressive Julia code has unexpectedly empowered even novice users to provide desired features in Julia, rather than haplessly bemoan their absence. One of my very first contributions to Julia was to implement elementary complex functions with correct branch cuts. Julia’s expressive syntax and native Unicode support allowed me to transcribe these functions directly from the code and equations from the scientific literature [pdf]. After some straightforward testing, the feature was accepted into the main repository, and the very same code, which maintains much of the notation and structure of the original paper, is now used in production in the Julia v0.2 point release. Julia allows for abstract concepts to be reused directly as code with minimal syntactic changes, which is both practical in that it simplifies code testing and debugging, and deeply satisfying intellectually to see ideas take form in executable statements.
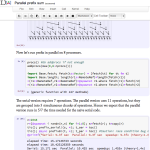
My experience was by no means atypical: the blurring of the traditional notions of active developer and passive end user, of abstract concepts and concrete code, is perhaps one of the most rewarding aspects of the Julia user experience. Many others have also contributed both to Julia itself and to Julia packages, providing functionality for such diverse disciplines as bioinformatics, chemistry, cosmology, finance, linguistics, machine learning, mathematics, statistics, and high performance computing. Collaborations are also beginning to form across traditional disciplinary boundaries, making packages like IJulia, a sophisticated web-based interface for Julia that grew out of a collaboration with the IPython team. IJulia’s web notebook interface provides a literate programming environment, integrating text, multimedia, code, and programmatically generated output in ways that allow novice and experienced programmers alike to rapidly see the results of tinkering with code.
IJulia, a Sophisticated Web-based Interface for Julia. Shown here is an IJulia notebook from Jiahao Chen (Source: Jiahao Chen)
Julia’s combination of elegance, power and a thriving community is precisely why it is a serious platform for big data applications. Julia now provides interfaces to code written in other languages such as Fortran, C, Python, R, and even Matlab, allowing programmers to interoperate with existing code. Julia also easily retrieves data from a variety of file formats, protocols and databases, such as HTTP, JSON, HDF5, and ODBC, allowing programmers to interface diverse data sources with minimal fuss. Developing these features in such a short time would not have been possible without a powerful language and the collective efforts of many developers around the world, who also have vested interests as users for their contributions to work correctly and be useful.
Julia programmers can access data, compute on it, and render the results in a single integrated environment that has all the building blocks necessary to develop high-performance big data applications, and yet is flexible enough to express ideas in clean and simple code
Julia also provides the means to compute efficiently on large data sets, thanks to its built-in parallel computing features such as one-sided message passing, mapreduce and distributed arrays. Processors can be dynamically added or removed to a master Julia process, both locally on symmetric multiprocessor systems and remotely on a computer cluster. Support for multiple paradigms of parallelism gives Julia users the freedom to customize scalable applications and simplifies deployment on both traditional clusters and cloud computing facilities. For example, MIT users can go to https://ijulia.csail.mit.edu:8000 (user certificates required), which provides an IJulia interface hosted on CSAIL’s OpenStack cloud server; others can use Julia from the web console of the Sagemath Cloud™ server. Rather than bother with downloading, building, and installing Julia, users can simply go to a cloud server where Julia is already deployed and start using Julia applications right away.
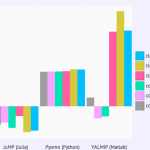
Julia’s capabilities, while still evolving rapidly, are already complete enough to write heavyweight number-crunching applications in. A notable example is JuMP, a numerical optimization package written by MIT Operations Research PhD students Miles Lubin and Iain Dunning [pdf]. JuMP uses Julia’s metaprogramming features to turn models input using symbolic algebraic expressions into low-level system calls to external solver libraries. As a result, JuMP can outperform its competition, matching the speed of industry-standard tools like AMPL while offering an expressive syntax that is much easier for new users to learn to use.
Comparative Performance of JuMP, a Numerical Optimization Package Written in Julia, Relative to AMPL, a Commercial Solver (Source: Miles Lubin and Iain Dunning.)
With Julia’s extensive web client/server functionality, JuMP can also be combined with user-friendly interfaces to provide seamless, interactive systems for solving problems. Iain’s Sudoku-as-a-Service website is a fun example: the user inputs a Sudoku puzzle, the server solves the Sudoku board using integer programming techniques [pdf] and returns the result. With fewer than 200 lines of readable code, optimization software is posted online for everyone to play with!
Sudoku-as-a-Service, An Example of Julia at Work (Source: Iain Dunning)
Here is a prototype for bringing computation to the world: imagine having websites or smartphone apps that compute the best way to run those errands between multiple places around town, to pack that suitcase, to optimize that schedule.
In less than two years, Julia’s high performance and expressive syntax have attracted a thriving user and developer community. Julia programmers can access data, compute on it, and render the results in a single integrated environment that has all the building blocks necessary to develop high-performance big data applications, and yet is flexible enough to express ideas in clean and simple code.
Why not download Julia today and try it out for yourself?
View post:
Open Big Data Computing with Julia | Intel Science & Technology …


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}