
Tupleware: Redefining Modern Analytics | Intel Science …

By Andrew Crotty, Alex Galakatos, and Tim Kraska, Brown University
The increasing prevalence of big data across all industries and sciences is causing a profound shift in the nature and scope of analytics. Increasingly complex computations, ranging from machine learning to predictive modeling, are fast becoming the norm. Users commonly express such tasks as a collection of user-defined functions (UDFs), preferably written in their language of choice (e.g., R, Python).
However, there is a fundamental discrepancy between the targeted users and the actual users of current analytics frameworks. Most importantly, current systems (Hadoop, Spark, Stratosphere, Myria, AsterixDB, etc.) are designed for cloud deployments that run on hundreds or thousands of cheap commodity machines, which represent the infrastructures operated by the Googles and Facebooks of the world. Yet non-tech companies like banks and retailers – or even the typical data scientist – rarely operate clusters of that size. In fact, it was reported in 2011 that the median Hadoop installation was smaller than 30 nodes; we therefore observe that typical users often prefer smaller clusters.
Given the prevalence of UDFs as part of complex analytics, it is even more surprising that effective support for UDFs is still weak to non-existent. UDFs are treated as either second-class citizens (by traditional DBMSs) or completely black boxes (by more recent analytics systems). Also, users are frequently forced to leave their favorite computing language, leading to a highly laborious development process and an inefficient end solution.
To address these issues, the Database Group at Brown University is developing Tupleware, a parallel high-performance UDF processing system that considers the computations, data, and hardware together to produce results as efficiently as possible. Tupleware is geared toward modern analytics and aims to (1) concisely express complex workflows, (2) optimize specifically for UDFs, and (3) leverage the characteristics of the underlying hardware.
Tupleware is a parallel high-performance UDF processing system that considers the data, computations, and hardware together to produce results as efficiently as possible.
Concisely express workflows
Tupleware takes a new approach that merges traditional SQL with functional programming to obtain the best of both worlds; we retain the optimization potential and familiarity of SQL while incorporating the flexibility and expressiveness of functional languages. Furthermore, Tupleware users are not bound to a single programming language. By building upon the popular LLVM compiler framework, the system can integrate UDFs written in any language that has an LLVM compiler, even mixing languages to compose a single job. Currently, C/C++, Python, Ruby, Haskell, Julia, R, and many other languages already have LLVM compilers, and we expect other languages to adopt LLVM in the near future.
Optimize for UDFs
Since the advent of DBMS research, a considerable amount of work has been devoted to the problem of SQL query optimization, but relatively little has been done to optimize custom UDF workflows. All traditional systems treat UDFs as black boxes, and thus they can never make informed decisions about how best to execute a given workflow. In contrast, Tupleware combines ideas from the database and compiler communities by performing UDF introspection, which allows the system to reason about the expected behavior of individual UDFs in order to achieve optimal performance. Thus, our system can optimize workflows without borders between UDFs, seamlessly integrating user-specified computations with the overarching control flow.
Leverage underlying hardware
Modern analytics require a variety of CPU-intensive computations. Whereas other systems neglect to efficiently utilize the available computing resources, Tupleware optimizes around all of the low-level characteristics of the underlying hardware, including SIMD vectorization, memory bandwidth, CPU caches, and branch prediction. In a process called program synthesis, our system translates workflows directly into compact and highly optimized distributed executables. This approach is built for maximum performance per node and avoids all of the overhead inherent in traditional systems.
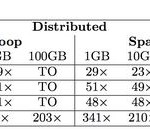
Our initial benchmarks, based on common machine learning algorithms, demonstrate the superior performance of Tupleware relative to alternative analytics platforms. In particular, we compare our system to the industry standard Hadoop, the in-memory analytics framework Spark, and a commercial column DBMS (System X). Tupleware outperforms these systems by up to three orders of magnitude in both distributed and single machine configurations.
Figure 1: Tupleware’s speedup over other systems (TO = timed out, FAIL = memory failure)
Tupleware is a research project under development by the Database Group at Brown University. For more information and updates about publications/releases, please join our mailing list at tupleware.cs.brown.edu.
Visit site –
Tupleware: Redefining Modern Analytics | Intel Science …


{kind=link}
{kind=link}
{kind=link}